简单动态字符串(SDS)和直接存储,但其编码方式可以是int、raw或者embstr,区别在于内存结构的不同。
结构为一个链表,记录头和尾的地址,元素不唯一,先入先出原则。
如创建一个 key = ‘numbers’,value = ‘1 three 5’ 的三个值的列表
1.ziplist实现 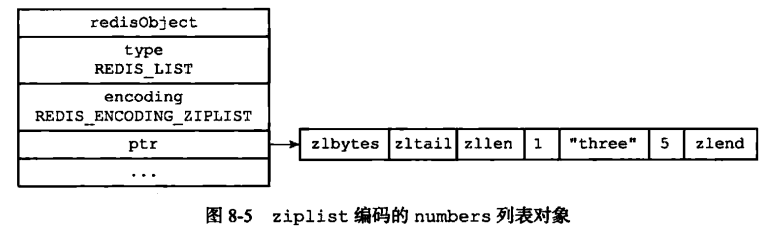
2.linkedlist实现 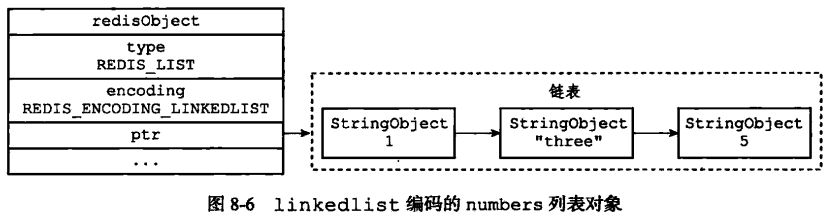
3.quicklist实现 3.2之后为quikclist实现 TODO
一个值为空的散列表。
1.intset实现 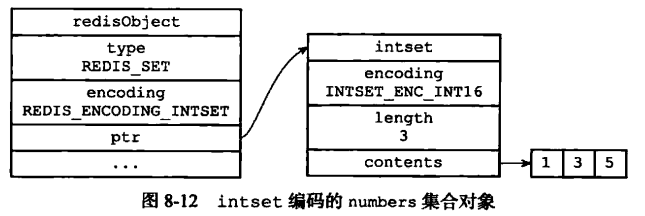
2.hashtable实现 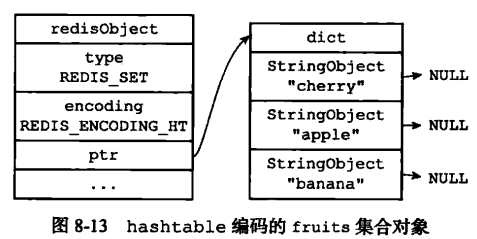
hash的key必须是唯一的
如存储一个{"name": "Tom", "age": 25, "career": "Programmer"}的对象
1.ziplist实现 
2.hashtable实现 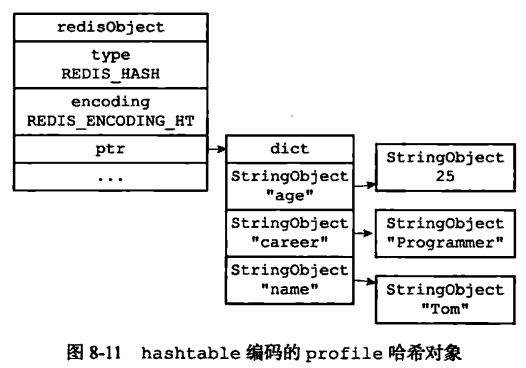
sorted set / zset 有序集合
1.ziplist实现  每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。
每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。
2.skiplist实现 实际是字典+跳跃表。  字典的键保存元素的值,字典的值则保存元素的分值;跳跃表节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。
字典的键保存元素的值,字典的值则保存元素的分值;跳跃表节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。
为何skiplist编码要同时使用跳跃表和字典实现?
跳跃表优点是有序,但是查询分值复杂度为O(logn);字典查询分值复杂度为O(1) ,但是无序,所以结合连个结构的有点进行实现。
虽然采用两个结构但是集合的元素成员和分值是共享的,两种结构通过指针指向同一地址,不会浪费内存。
压缩列表(ziplist)
本质上就是一个字节数组,是Redis为了节约内存而设计的一种线性数据结构,可以包含任意多个元素,每个元素可以是一个字节数组或一个整数。
跳跃表(skiplist)
 原始链表的查询时需要从头到尾依次遍历遇到所有节点,性能较差。
原始链表的查询时需要从头到尾依次遍历遇到所有节点,性能较差。
 可以给每个节点都维护一组指向其后每一个节点的指针,这样就可以通过任意一个节点,访问到其后的任意一个节点了,但是同时也会发现,所有节点需要维护的指针数目是(n-1)!。
可以给每个节点都维护一组指向其后每一个节点的指针,这样就可以通过任意一个节点,访问到其后的任意一个节点了,但是同时也会发现,所有节点需要维护的指针数目是(n-1)!。
Redis跳跃表实现 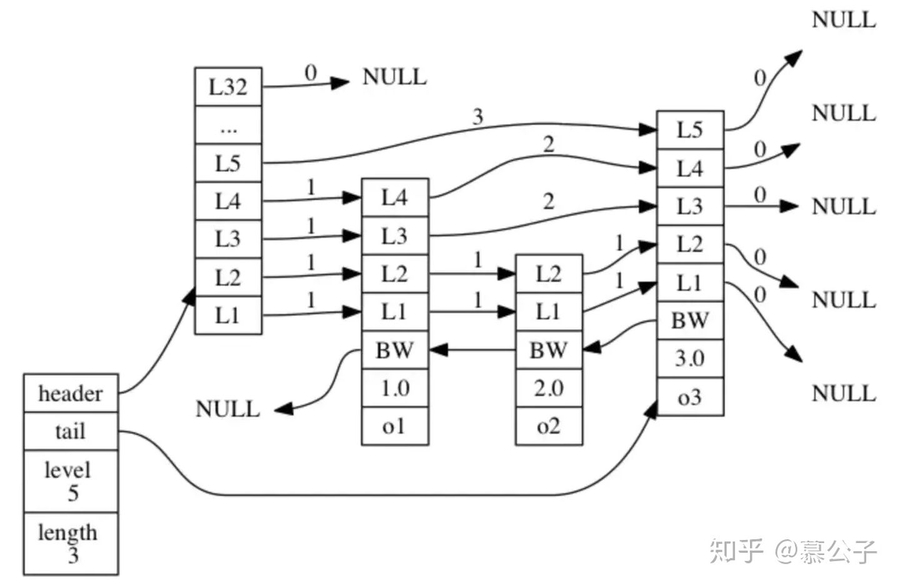
每个节点上都保存了一个用于指向其后节点的指针数组;
设置一个指向前一个节点的指针(方便逆向获取数据,如zrevrank、zrevrange);
创建了一个length和一个level属性用于快速查询跳表的节点数目和指针数组的最大长度;
节点中还会保存前向指针跳过的节点数span,可以用于分页。
最大32层指针,是因为生成指针的期望是1/4,所以2^32个节点中,才会有一个32层指针的节点,32层完全够用。
Redis 渐进式哈希
redis中会默认存在两个哈希表,开始使用时默认使用哈希表1,哈希表2未分配空间,当需要rehash时,
但第二步涉及大量数据拷贝,会导致redis线程阻塞,因此第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。 所以redis dick rehash过程中数据的迁移并不是一步完成的。
1.定期删除
redis 默认是每隔 100ms 就随机抽取一些设置了过期时间的 key,检查其是否过期,如果过期就删除。
2.惰性删除
在获取某个 key 的时候,redis 会检查一下 ,如果这个 key 设置了过期时间,并且已经过期了,那么就直接删除,返回空。
ps.如果大量的key没有被扫描到,且已过期,也没有被再次访问,即没有走惰性删除,这些大量过期 key 堆积在内存里,导致 redis 内存块耗尽了:redis提供内存淘汰机制(如LRU)。
优点:
数据存放在内存中,读写速度很快,采用单线程结构,防止了因多线程竞争可能出现的问题和消耗。
数据类型丰富,五种基础数据类型,并且有很多很有用的扩展数据类型,如位图,HyperLogLog,发布订阅,GEO 等。
功能丰富,提供键过期,简单事务,Lua 脚本管理,Pipeline 等功能。
数据可持久化,可通过 RDB 和 AOF 两种方式进行数据持久化。
提供主从复制,可利用集群,哨兵构建高可用的分布式架构。
缺点:
主从复制采用全量复制,若快照文件过大,对集群的服务能力会产生较大影响。
采用单线程,避免了不必要的上下文切换和竞争条件,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
使用多路I/O复用模型,非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架
官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
RDB方式 把数据以快照的形式保存在磁盘上。通常采用的是fork创建子进程来进行持久化。提供手动触发和自动触发两种方式。通常用到 BGSAVE 命令来fork一个子进程进行备份,而 SAVE 会阻塞 Redis 导致备份期间不能执行其他命令。
优点:全量备份,非常适合用于进行备份和灾难恢复;最大化 Redis 的性能,只需要fork出一个子进程,父进程无须执行任何磁盘 I/O 操作;RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。 缺点:快照持久化期间修改的数据不会被保存,可能丢失数据。数据集比较庞大时, fork() 可能会非常耗时。
AOF方式 AOF 会把 Redis 服务器每次执行的写命令记录到一个日志文件中,当服务器重启时再次执行 AOF 文件中的命令来恢复数据。默认情况下 AOF 功能是关闭的,Redis 只会通过 RDB 完成数据持久化的。也可以手动触发或者自动触发。
AOF 文件的写入流程可以分为以下 3 个步骤:
命令追加(append):将 Redis 执行的写命令追加到 AOF 的缓冲区 aof_buf
文件写入(write)和文件同步(fsync):AOF 根据对应的策略将 aof_buf 的数据同步到硬盘
文件重写(rewrite):定期对 AOF 进行重写,从而实现对写命令的压缩
优点:数据更完整,安全性更高,秒级数据丢失;AOF 文件是一个只进行追加的命令文件,且写入操作是以 Redis 协议的格式保存的,内容是可读的,适合误删紧急恢复。 缺点:对于相同的数据集,AOF 文件的体积要远远大于 RDB 文件,数据恢复也会比较慢;根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB。
TODO