system-design
设计模式六大原则
单一职责原则(Single Responsibility Principle, SRP)
就一个类而言,应该仅有一个引起它变化的原因。
如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这种耦合会导致脆弱的设计,当变化发生时,设计会遭受到意想不到的破坏。
开放‑封闭原则(Open-Closed Principle, OCP)
是说软件实体(类、模块、函数等待)应该可以扩展,但是不可修改(Open for extension, closed for modification)。
无论模块多么地“封闭”,都会存在一些无法对之封闭的变化。既然不可能完全封闭,设计人员必须对于他设计的模块应该对哪种变化封闭做出选择。他必须先猜测出最有可能发生的变化种类,然后构造抽象来隔离那些变化。在我们最初编写代码时,假设变化不会发生。当变化发生时,我们就创建抽象来隔离以后发生的同类变化。面对需求,对程序的改动是通过增加新代码进行的,而不是更改现有的代码。
依赖倒置原则(Dependence Inversion Principle,DIP)
高层模块不应该依赖底层模块。两个都应该依赖抽象。抽象不应该依赖细节。细节应该依赖抽象。针对接口编程,不要对实现编程。
举例:访问数据库逻辑写到一个函数(底层模块)用以复用,业务层(高层模块)进行调用。如果需要更换不同数据库或者不同连接池等等,但此时高层模块与底层模块耦合在一起。办法就是在高层模块和底层模块之间做一层抽象(接口或者抽象类)。
接口隔离原则(Interface Segregation Principle, ISP) 使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。
根据接口隔离原则,当一个接口太大时,我们需要将它分割成一些更细小的接口,使用该接口的客户端仅需知道与之相关的方法即可。每一个接口应该承担一种相对独立的角色,不干不该干的事,该干的事都要干。这里的“接口”往往有两种不同的含义:一种是指一个类型所具有的方法特征的集合,仅仅是一种逻辑上的抽象;另外一种是指某种语言具体的“接口”定义,有严格的定义和结构,比如Java语言中的interface。
里式替换原则(Liskov Substitution Principle, LSP)
子类型必须能够替换掉它们的父类型。
也就是说,在软件里面,把父类都替换成它的子类,程序的行为没有变化。只有当子类可以替换掉父类,软件单位的功能不受到影响时,父类才能真正被复用,而子类也能够在父类的基础上增加新的行为。
迪米特法则(Law of Demeter, LoD)
如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。根本思想是强调了类之间的松耦合。
接口隔离原则和单一职责原则的区别
单一职责原则注重的是职责,而接口隔离原则注重的是对接口依赖的隔离。
单一职责原则主要是约束类,它针对的是程序中的实现和细节;接口隔离原则主要约束接口,主要针对抽象和程序整体框架的构建。
设计模式
简单工厂、工厂方法和抽象工厂区别
简单工厂:唯一工厂类,一个产品抽象类,工厂类的创建方法依据入参判断并创建具体产品对象。(举例:一个汽车生产商承接了各种品牌汽车的生产,当为宝马汽车生产产品时只需要在调用该工厂的方法时传入参数“BM”即可创建相应产品,现用简单模式来模拟实现)
工厂方法:多个工厂类,一个产品抽象类,利用多态创建不同的产品对象,避免了大量的if-else判断。(举例:一个汽车生产商承接了各种品牌汽车的生产,将其原有的汽车工厂进行分割,为每种品牌的汽车各自设立一个子工厂,宝马汽车工厂专门生产宝马汽车,奔驰汽车厂专门生产奔驰汽车,如果再次承接了其他品牌汽车的生产合作,只需要添加一个对应的工厂即可,无需对原有的工厂进行修改)
抽象工厂:多个工厂类,多个产品抽象类,产品子类分组,同一个工厂实现类创建同组中的不同产品,减少了工厂子类的数量。(举例:一个汽车生产商承接了各种品牌汽车的生产,又可以生产多种种类的汽车,像公共汽车、小轿车等,相同品牌的汽车构成一个产品族,而相同类型的汽车又构成了一个产品等级结构,使用抽象工厂模式实现该应用,如宝马汽车厂生产宝马公汽和小轿车,奔驰汽车厂生产奔驰公汽和小轿车)
文章海量评论分页设计
场景:
文章的评论量非常大, 比如说一篇热门文章就有几百万的评论, 设计一个后端服务, 实现评论的时序展示与分页。
设计:
1.不支持页码跳转:传评论id 用 offset 实现翻页,(文章id, 评论id) 建联合索引,评论 id 需递增。
如果表中存在连续的数字列并为索引,那么通过页码即可计算出此字段的范围,直接作范围查询即可:
2.支持页码跳转:不能做精准深分页,否则压力太大,在50或100页后数据分页是否可以不完全精确,假如可以,那么缓存深页码的起始评论 id。
海量数据出现频率
TODO
分库分表下的分页查询
每张表查 N 条数据,数据在服务层进行内存排序,得到数据全局视野,再取目标页数据,便能够得到想要的全局分页数据。
缓存重建
互斥锁:只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可
永不过期:从缓存层面来看,确实没有设置过期时间,所以不会出现热点 key 过期后产生的问题,也就是“物理”不过期。从功能层面来看,为每个 value 设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
六边形架构
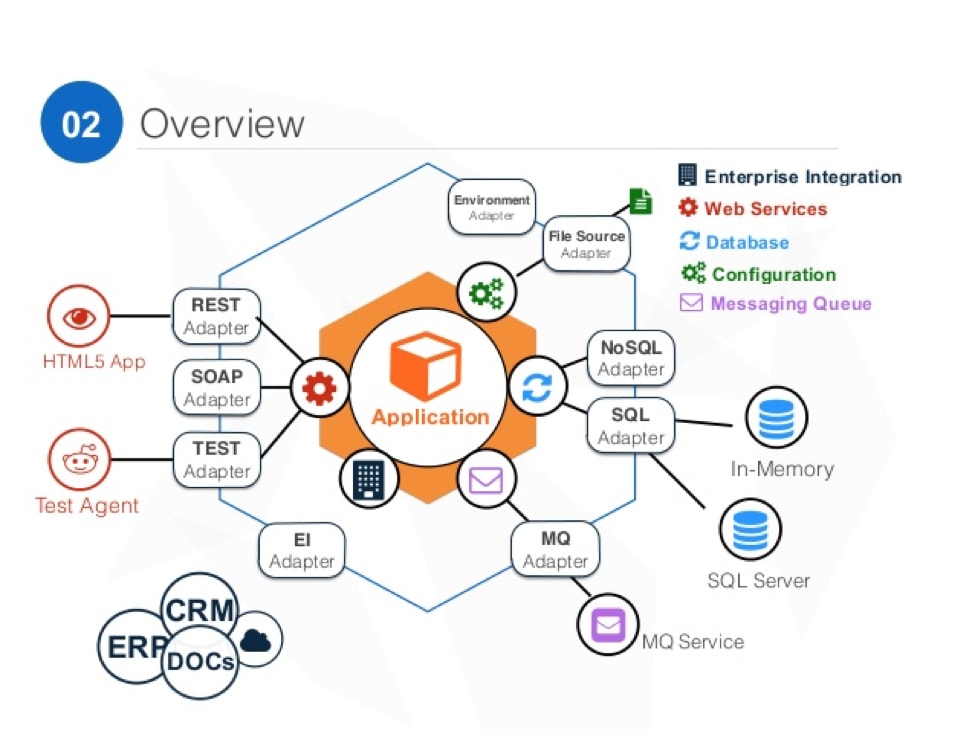
在六边形架构风格中,应用程序的内部(中间的橙色六边形)包含业务规则,基于业务规则的计算,领域对象,领域事件等。而外部的,也是我们平时最熟悉的诸如REST,SOAP,NoSQL,SQL,Message Queue等,都通过一个端口接入,然后在内外之间有一个适配器组成的层,它负责将不同端口来的数据进行转换,翻译成领域内部可以识别的概念(领域对象,领域事件等)。
内部不关心数据从何而来,不关心数据如何存储,不关心输出时JSON还是XML,事实上它对调用者一无所知,它可以处理的数据已经是经过适配器转换过的领域对象了。
SOLID原则
单一责任原则(The Single Responsibility Principle)
一个类只应承担一种责任。
开放封闭原则(The Open Closed Principle)
实体应该对扩展是开放的,对修改是封闭的。
举例:比如系统支付方式有多种,每新增一种需要修改原有代码,可以抽离出来一个PayHandler接口,这样新增支付方式只需要新增一个PayHandler实现类即可,不用改动原有代码。
里氏替换原则(Liskov Substitution Principle)
一个对象在其出现的任何地方,都可以用子类实例做替换,并且不会导致程序的错误。
接口分离原则(The Interface Segregation Principle)
客户(client)不应被强迫依赖它不使用的方法。即,一个类实现的接口中,包含了它不需要的方法。将接口拆分成更小和更具体的接口,有助于解耦,从而更容易重构、更改。
依赖倒置原则(The Dependency Inversion Principle) 高层次的模块不应依赖低层次的模块,他们都应该依赖于抽象;抽象不应依赖于具体实现,具体实现应依赖抽象。
举例:数据库连接Driver、六边形架构、MVC模式中面向接口编程
缓存穿透、缓存击穿和缓存雪崩
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
接口层增加校验,如用户鉴权校验,id做基础校验
布隆过滤器
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)
缓存击穿是指缓存中没有但数据库中有的热点数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
设置热点数据永远不过期
加互斥锁
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中
设置热点数据永远不过期
加互斥锁
缓存热点问题解决方案
问题描述: 如redis集群的热点key(一个key map到一台redis机器上)会导致局部机器是热的,其他机器是冷的
解决方案: 1.可以采用多级缓存,将热点key-value缓存到本地缓存上,这样不用再访问redis机器了,利用Redis自带的消息通知机制,对于热点Key客户端建立一个监听,当热点Key有更新操作的时候,客户端也随之更新。 2.可以在程序层面加工key,如key#redis1、key#redis2、key#redis3。
读写分离
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。
优点
提高数据库的并发处理能力;
避免写请求锁表阻塞读请求;
避免单点,提高数据库的可用性;
读写分离和缓存比较
价格,缓存基于内存价格较贵,而主从库基于磁盘价格便宜
缓存存在未命中情况,仍然需要从数据库读取,数据库写入会影响读取性能
缓存更多的是抵挡请求对DB的压力,针对热点数据
微服务
微服务 (Microservices) 就是一些协同工作小而自治的服务。
小,小就是简单,简单到通过名字或者定义就可以知道它大概能干什么事了,而且只干这一件事
自治,独立部署、独立运行,并能独立完成一个业务闭环
优点
技术异构性。不同服务内部的开发技术可以不一致
隔离性。一个服务不可用不会导致另一个服务也瘫痪,因为各个服务是相互独立和自治的系统
可扩展性。可以只对那些影响性能的服务做扩展升级
简化部署。单体服务几百万行代码,即使修改了几行代码也要重新编译整个应用,这显然是非常繁琐的,部署风险更高
易优化。代码量不会很大,容易重构
缺点
分布式带来的复杂性,如分布式数据库、分布式事务
测试挑战。对微服务进行测试,需要启动它依赖的所有其他服务
涉及多个服务时部署复杂
Service Mesh 服务网格
TODO
服务网格(Service Mesh)是处理服务间通信的基础设施层。它负责构成现代云原生应用程序的复杂服务拓扑来可靠地交付请求。在实践中,Service Mesh 通常以轻量级网络代理阵列的形式实现,这些代理与应用程序代码部署在一起,对应用程序来说无需感知代理的存在。
如果用一句话来解释什么是 Service Mesh,可以将它比作是应用程序或者说微服务间的 TCP/IP,负责服务之间的网络调用、限流、熔断和监控。对于编写应用程序来说一般无须关心 TCP/IP 这一层(比如通过 HTTP 协议的 RESTful 应用),同样使用 Service Mesh 也就无须关心服务之间的那些原本通过服务框架实现的事情,比如 Spring Cloud、Netflix OSS 和其他中间件,现在只要交给 Service Mesh 就可以了。
接口加密方案
TODO
Last updated